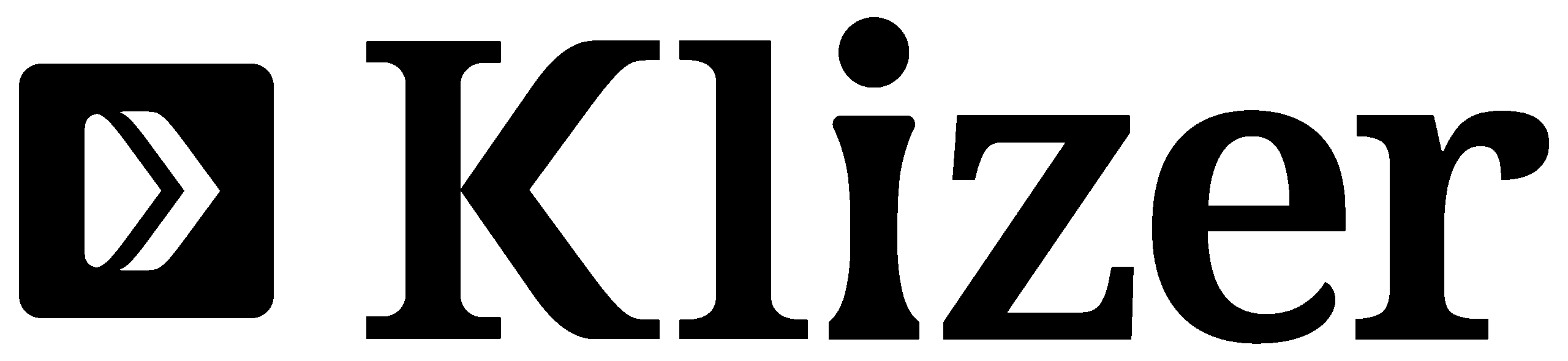

Every year, businesses lose an average of $9.7 million due to inaccurate or incomplete product information. Missing specs, vague descriptions, and inconsistent attributes cost you conversions, inflate your return rate, and erode customer trust before checkout.
But in 2026, there is a second, more urgent cost that most teams are still catching up to: AI invisibility.
A recent audit found that 54% of brands ranking well on Google are not cited at all by AI systems like ChatGPT, Perplexity, or Google’s AI Overviews. These brands have invested years into SEO. They rank on page one. And yet when a shopper asks an AI assistant for a recommendation, they simply don’t appear.
The reason is almost always the same: product data structured for human browsing, not for AI interpretation.
AI shopping is no longer an emerging trend, it is the dominant new discovery channel. Traffic from generative AI sources grew 1,300% year-over-year through 2024 and has continued compounding since. During Cyber Week 2025, 20% of all global orders were influenced by AI agents or shopping assistants. ChatGPT alone processes an estimated 50 million shopping queries daily, and LLM-referred traffic converts at 2.47%, above both Google organic and Meta Ads. By 2026, Morgan Stanley’s prediction that nearly half of online shoppers would use AI shopping agents is well on its way to reality.
The solution to both the old problem and the new one is the same: AI-driven product data enrichment, transforming raw, incomplete catalog data into structured, accurate, channel-ready content that both human shoppers and AI engines can use confidently.
ON THIS PAGE
What is AI Product Enrichment?
“AI product data enrichment” describes two related but distinct processes. The most successful strategies in 2026 address both simultaneously.
Definition A: Using AI to enrich product data. This means using LLMs, computer vision, and NLP to improve catalog quality at scale: generating descriptions from minimal inputs, extracting attributes from product images, standardising inconsistent supplier terminology, and classifying products into the correct taxonomy automatically.
Definition B: Enriching data so AI systems can understand it. AI shopping engines don’t rank products by domain authority. They surface products by parsing structured, machine-readable data and matching it against conversational queries. A shopper asking “What’s a good carry-on suitcase under $200 with spinner wheels that fits overhead bins?” isn’t submitting keywords; they’re submitting a precise attribute checklist. If your listing doesn’t contain those attributes in a parseable format, your product is invisible to that query, regardless of how good it actually is.
Research shows GPT-4 accuracy on product queries jumps from 16% to 54% when content uses structured data, a 3x improvement from formatting alone.
| Attribute | Raw | AI-Enriched |
| Title | “WE-BT-7700 Earbuds” | “Sony WF-1000XM5 True Wireless Earbuds, Noise Cancelling, 24hr Battery, Multipoint Bluetooth” |
| Attributes | Color: Black | Color: Midnight Black; Bluetooth: 5.3; Codecs: LDAC, AAC; Water resistance: IPX4; Charging: USB-C + Qi |
| Category | Electronics > Headphones | Electronics > Headphones > True Wireless Earbuds |
Why Manual Enrichment Is Broken at Scale
For catalogs of any meaningful size, manual enrichment is not just slow, it is structurally incapable of meeting modern standards.
One mid-sized fashion retailer reported spending 350+ hours per season updating just color and size attributes across channels. That excludes descriptions, lifestyle tags, localised content, or technical specs. Automated product data enrichment can process those same updates at under $1 per SKU, the economics do not close.
The harder problem is data readiness. AI enrichment cannot save a corrupted foundation. Feeding inconsistent, duplicated, or structurally broken data into an AI pipeline produces consistently wrong enrichment at scale. The most common supplier data problems: enigmatic model numbers used as product names, duplicate descriptions copied and pasted across variants, missing critical specs, and inconsistent units of measurement.
Before any AI product data enrichment automation pipeline can function reliably, you need a data readiness audit, a completeness score across your catalog that identifies exactly where the gaps are and addresses structural issues before the AI layer begins. Clear the land before you build.

How Does AI-Driven Product Data Enrichment Work?
Most discussions treat enrichment as a single action: “run AI on your catalog.” Sustainable, scalable enrichment requires five connected stages.
Stage 1: Ingestion and audit. All data sources, supplier CSVs, ERP exports, PDFs, and product images are ingested and scored for completeness. Duplicates are identified, schemas are normalised, and missing attribute gaps are mapped.
Stage 2: AI extraction and generation. NLP extracts structured attributes from unstructured text. Computer vision generates color, material, and style attributes from product photography. LLMs produce enriched titles, benefit-led descriptions, and customer-language attribute phrasing from minimal inputs.
Stage 3: Standardisation and taxonomy mapping. Generated attributes are standardised into consistent vocabularies across the catalog. Products are classified into the correct taxonomy for each target channel, Google, Amazon, and your site, automatically.
Stage 4: Confidence scoring and governance. Every AI-generated attribute receives a confidence score. High-confidence enrichments are auto-approved; low-confidence ones are flagged for human review. This gives you AI speed without removing the oversight that accuracy requires for technical specs, regulated categories, and brand-critical content. Audit trails, version control, and rollback capability are essential for enterprise deployments.
Stage 5: Syndication and continuous monitoring. Enriched data is distributed to all channels through live integrations. Automated monitoring detects when source specifications change and re-queues affected SKUs for enrichment, without manual intervention.
Read More: Product Data Enrichment in eCommerce: A Complete Guide
How Does Automated Product Data Enrichment Get Your Products Cited by AI?
SEO rank and AI visibility are now fully disconnected. A brand can hold the top three Google positions for its target keywords and still be absent from every AI-generated recommendation for those exact queries. In 2026, that gap is no longer theoretical; it is showing up directly in revenue reports.
AI engines decide what to recommend differently from search engines:
- 41% of recommendation weighting: authoritative “best of” editorial mentions
- 18%: awards and third-party recognition
- 16%: review volume and quality
- Structured data quality: the deciding factor for otherwise equal candidates
Structured data quality is a direct output of how thoroughly your product data has been enriched. This is the link most brands are still missing.
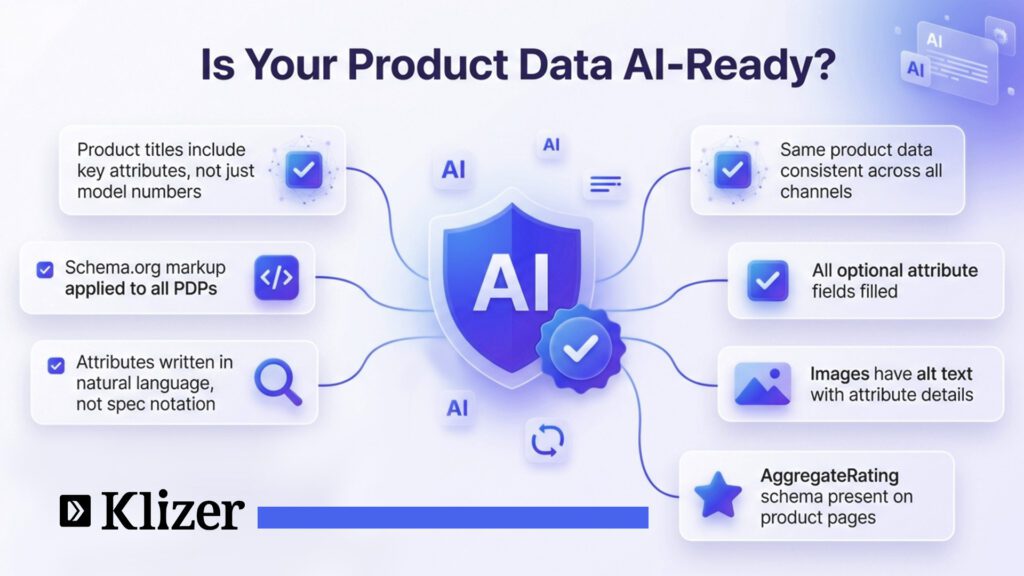
What AI-ready product data looks like in 2026:
Natural-language attribute phrasing. “Connects via Bluetooth 5.3, supporting two devices simultaneously” outperforms “connectivity: BT5.3”, AI engines parse concepts, not spec notation.
Schema.org structured markup. Complete Product, Offer, and AggregateRating schema on every PDP is the primary way AI crawlers extract and trust your data.
Channel consistency. Conflicting product information across your website, Amazon, and Google Shopping sends mixed signals that reduce AI confidence across all of them. One consistent enriched attribute set creates the authoritative signal that AI engines prioritise.
Complete optional attributes. Every optional field you leave empty is context that an AI engine cannot use to match your product to a relevant query.
To measure GEO performance, track AI citation rate by SKU, brand share of voice in AI-generated category results, attribute completeness scores, and run regular manual audits of your top queries directly in ChatGPT and Perplexity.
What ROI Can You Expect From AI Product Data Enrichment Automation?
Annual ROI = [(Conversion lift × Revenue)
- (Return rate reduction × Return handling cost)
- (Hours saved × Team hourly cost)
- (New AI-channel revenue)] ÷ Enrichment tool and implementation cost
Worked example, 10,000 SKU catalog, $8M revenue:
| Factor | Estimate |
| Conversion rate lift (conservative 1.5%) | $120,000 |
| Return rate reduction (18% → 12%) | $480,000 |
| Manual hours saved (1,400 hrs/year × $45) | $63,000 |
| New AI-channel revenue (est. 5%) | $400,000 |
| Total annual benefit | $1,063,000 |
| Enrichment tool cost | ~$98,000 |
| Estimated ROI | ~985% |
These are conservative estimates. Businesses that implemented automated product data enrichment over the past two years report saving up to 70% of manual data management time. McKinsey data shows product data errors cost up to 23% in clicks and 14% in conversions. A 40% reduction in return rates is achievable with complete, accurate product content.
What Is the Future of Automated Product Data Enrichment?
Today’s enrichment pipeline is still largely triggered by human events, a new product ingested, a batch job scheduled. The next phase, already emerging in 2026, removes that dependency entirely.
Agentic AI enrichment means autonomous agents that monitor your catalog continuously, detecting supplier specification changes, tracking competitor attribute gaps, watching for regulatory updates, and identifying SKUs whose conversion rate has dropped, and initiating enrichment automatically, without a human trigger.
The agentic commerce market was valued at $547 million in 2025 and is on a trajectory toward $5.2 billion by 2033. Over 1 million Shopify merchants have already opted into OpenAI’s Instant Checkout, enabling autonomous purchasing directly within ChatGPT. The infrastructure for autonomous commerce is being built right now, and enriched, structured product data is the entry ticket.
The prerequisite is a PIM system as a single source of truth: a governed data model with defined attribute schemas and approval workflows that autonomous agents can read from and write to reliably. Without that foundation, autonomous enrichment has no stable target state to work toward.
How to Implement AI-Driven Product Data Enrichment in 90 Days
Days 1–30, Audit and prioritise. Run a completeness audit on your catalog. Identify your top 15% of SKUs by revenue as your first enrichment target. Address foundation data issues, deduplication, unit normalisation, and schema cleanup. Manually test your top 20 product queries in ChatGPT and Perplexity to baseline your current AI visibility.
Days 31–60, Deploy and govern. Implement your AI enrichment pipeline with confidence scoring and human review for low-confidence attributes. Apply Schema.org markup to your top-traffic PDPs. Set attribute completeness targets per channel.
Days 61–90, Measure and expand. Compare conversion rate and return rate for enriched vs. unenriched SKUs. Track AI citation rate trends. Calculate actual ROI against the framework above. Prioritise the next SKU batch based on revenue impact and enrichment gap size.
Conclusion
Every enriched SKU compounds in value: it improves AI discoverability today, reduces your cost-per-conversion this quarter, and builds the data foundation for the autonomous enrichment workflows that are becoming standard in 2026. The $9.7M problem is solvable. The AI visibility gap is closeable. Both require the same investment: structured, AI-driven product data enrichment, executed systematically across your catalog.
If you are looking for expert help to have custom product data enrichment for your ecommerce business, reach out to us now!





